Contents Science Lab

November 10, 2020: Our work on Imageability estimation using visual and language features by C. Matsuhira et al. got presented at ICMR2020.
October 16, 2020: Our work on sentence imageability-aware image captioning by K. Umemura et al. got accepted by MMM2021.
April 1, 2020: Contents Science Lab was established.
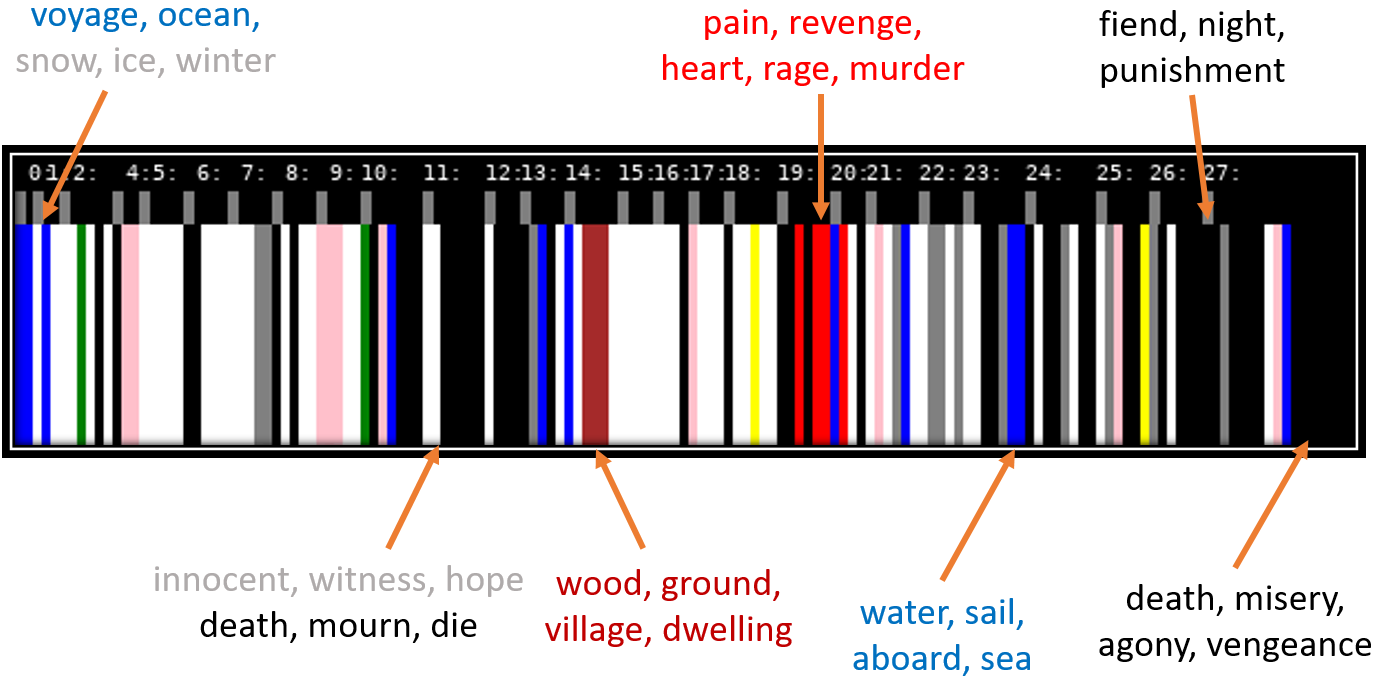
In this research, we colorize pages of books according to human perception in order to summarize and compare book contents.

In this research, we incorporate psycholinguistics into image captioning in order to tailor captions to different applications.
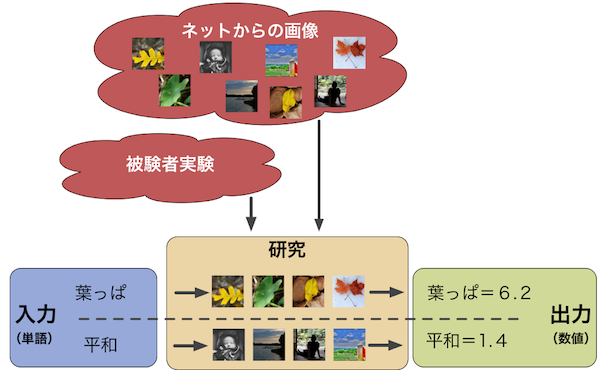
In this research, we model the human perception of the semantic gap for use in affective computing.

In this research, we analyze the phonetic characteristics and human perception of mimetic words used in Japanese to describe human gait.
View-aware Cross-modal Distillation for Multi-view Action Recognition. Trung Thanh Nguyen, Yasutomo Kawanishi, Vijay John, Takahiro Komamizu, Ichiro Ide. IEEE/CVF Winter Conference on Applications of Computer Vision, pp.1-10, March 2026.
放送映像アーカイブから見える社会変化の予兆. 井手 一郎. 社会システム・価値観変化の予兆-予兆学シンポジウム(YOCHOU2025)講演録,原邦彦,大平英樹,大平徹,鍵山直人編, pp.33-46, January 2026.
Hierarchical Global-Local Fusion for One-stage Open-vocabulary Temporal Action Detection. Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, Ichiro Ide. ACM Transactions on Multimedia Computing, Communications, and Applications, January 2026.
MultiSensor-Home: Benchmark for Multi-modal Multi-view Action Recognition in Home Environments. Trung Thanh Nguyen. ACM International Conference on Multimedia in Asia, pp.1-5, December 2025.
Q-Adapter: Visual Query Adapter for Extracting Textually-related Features in Video Captioning. Junan Chen, Trung Thanh Nguyen, Takahiro Komamizu, Ichiro Ide. ACM International Conference on Multimedia in Asia, pp.1-10, December 2025.
Quantifying visual impressions of words based on real-world data analysis. Ichiro Ide. 27th International Conference on Information Integration and Web Intelligence (iiWAS2025) / 23rd International Conference on Advances in Mobile Computing and Multimedia Intelligence (MoMM2025), December 2025.
Origami Crease Recognition for Automatic Folding Diagrams Generation. Hitomi Kato, Hirotaka Kato, Takatsugu Hirayama, Takahiro Komamizu, Ichiro Ide. Pattern Recognition and Computer Vision, 16175(2), pp.16-31, December 2025.
Semantic Alignment on Action for Image Captioning. Da Huo, Marc A Kastner, Takatsugu Hirayama, Takahiro Komamizu, Yasutomo Kawanishi, Ichiro Ide. IEEE Access, 13(2025), November 2025.
Semantic Alignment on Action for Image Captioning. Da Huo, Marc A Kastner, Takatsugu Hirayama, Takahiro Komamizu, Yasutomo Kawanishi, Ichiro Ide. IEEE Access, 13(2025), November 2025.
Lip Shape-Aware Word Selection for Lyric Translation. Kotaro Ikeda, Chihaya Matsuhira, Hirotaka Kato, Marc A. Kastner, Takatsugu Hirayama, Takahiro Komamizu, Ichiro Ide. Pattern Recognition and Computer Vision, Vol.16175, p.48–62, November 2025.