Computational Measurement of Perceived Pointiness of Pronunciation
Chihaya Matsuhira*, Marc A. Kastner, Takahiro Komamizu, Ichiro Ide,
Yasutomo Kawanishi, Takatsugu Hirayama, Keisuke Doman, and Daisuke Deguchi
*Corresponding author: matsuhirac (at) cs.is.i.nagoya-u.ac.jp
Link to our paper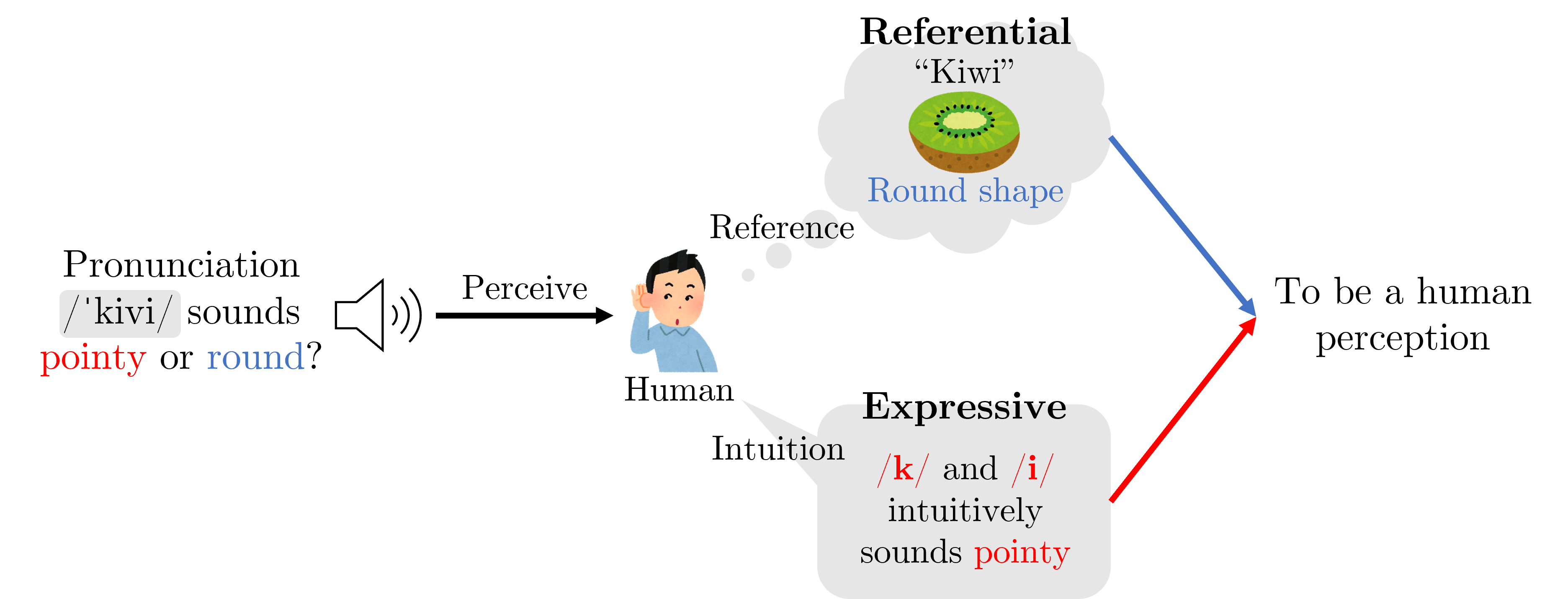
Abstract
Sound symbolism is a well-researched topic of psycholinguistics, which tries to comprehend the connection between the sound of a word and its meanings.
The Bouba-Kiki effect, one form of sound symbolism, claims that people perceive the pronunciation of ``Kiki'' as pointier than that of ``Bouba.''
There is no research that focuses on modeling such perception, i.e., how pointy a pronunciation sounds to humans, through computational and data-driven approaches.
To address this, this paper first proposes the novel concept of ``phonetic pointiness'' defined as how pointy a shape humans are most likely to associate with a given pronunciation.
We then model this phonetic pointiness from computational and data-driven approaches to calculate a score for an arbitrary pronunciation.
There are three proposed models: a referential model, an expressive model, and a combined model, which integrates the previous two. The idea comes from an existing psycholinguistic classification of two types of sound symbolisms: referential symbolism and expressive symbolism, where the former relates to vocabulary knowledge, while the latter is based on pure human intuition.
The proposed models are constructed only with image and language data available on the Web, therefore not requiring task-specific human annotations.
We evaluate these models through a crowd-sourced user study, finding a promising correlation between human perception and the phonetic pointiness calculated by the proposed models.
The results indicate that human perception can be modeled better by combining both types of sound symbolisms.
Furthermore, by observing the behaviors of the models, we show several possible use-cases, such as product naming and psycholinguistic research, which can be a useful insight to further studies and applications.
Experimental Data
- 400 pseudo-words used in our phoneme experiment: Download
- 400 pseudo-words used in our length experiment: Download
- List of the words and modified Tags in Emoji sub-datasets:
Fruits&Vegetables, Animals
Citation
Chihaya Matsuhira, Marc A. Kastner, Takahiro Komamizu, Ichiro Ide, Yasutomo Kawanishi, Takatsugu Hirayama, Keisuke Doman, and Daisuke Deguchi, Computational Measurement of Perceived Pointiness of Pronunciation. Multimedia Tools and Applications 83, 26183-26210 (2023). https://doi.org/10.1007/s11042-023-15732-z