Contents Science Lab

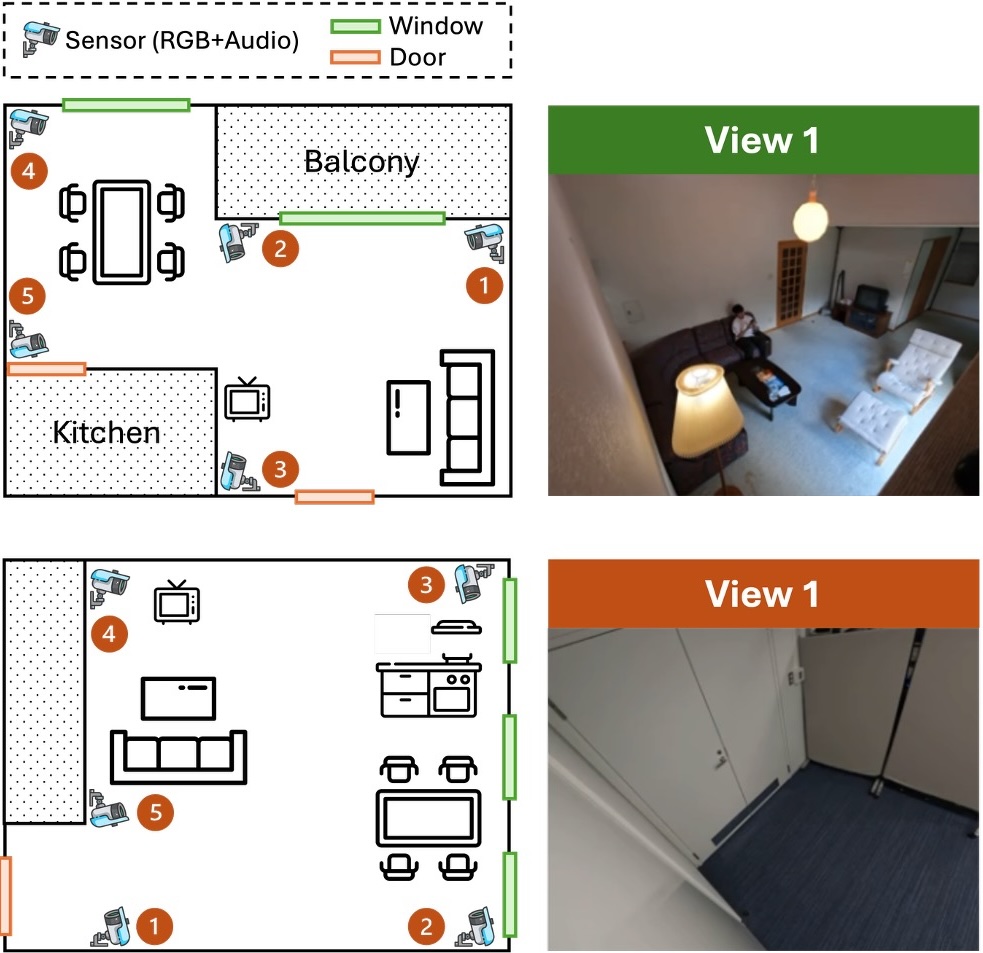
A wide-area multi-modal multi-view dataset for action recognition and transformer-based sensor fusion research.

This is a dataset composed of multi-channel audio data and panorama image sequence recorded for approximately 8 minutes in a closed 3D environment with five Sunda zebra finches (Taeniopygia guttata), at a facility in Hokkaido University, located in Sapporo, Japan.

We have built and released a food image dataset composed of images of ten food categories taken from 36 angles named NU FOOD 360x10. The images were assigned target values of their attractiveness through subjective experiments. This dataset is used in our project on estimating food attractiveness.

We built the dataset upon the MS-COCO dataset by estimating the semantic contents of images and captions and using this to augment the dataset toward image collection captioning. To construct a dataset for the proposed task, we implement and compare two approaches based on image classification and image-caption retrieval.

We built a framework for genre-adaptive near-duplicate video segment detection.

We have built and released a video dataset where gaits are expressed by various onomatopoeias according to their appearance. Each gait is annotated both by external judgement as well as the actors own judgment. This dataset is used in our project on mimetic words.
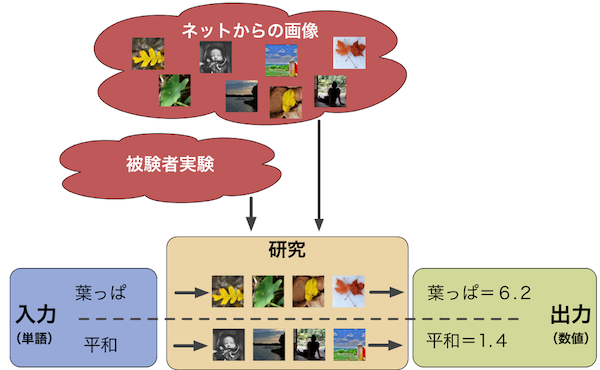
We developed a method for estimating the psycholinguistic concept of imageability for arbitrary words using data-mining on three modalities: visual features, textual features and phonetic features. We have furthermore published a preliminary tri-modal imageability dataset. These sources are part of our projects on imageability estimation and sentence imageability-aware image captioning.