Contents Science Lab

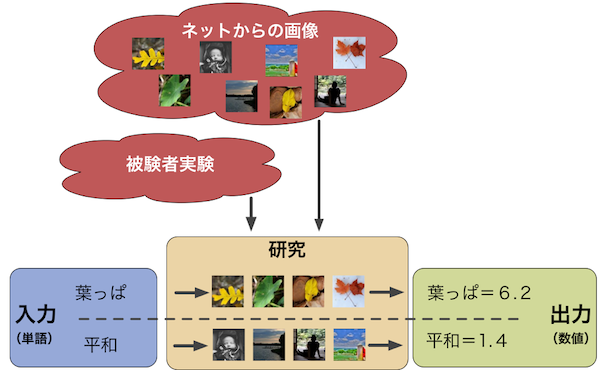
The semantic gap is the lack of coincidence between the information one can extract from data and its interpretation. For a machine it is often challenging to select the best fitting wording out of a group of candidates: For an image of a car, the tag “Vehicle” might be too vague, while the model number might be too specific. An understanding of the visual implications of tag can help to decide the correct degree of abstractness.
In this research, we estimate a measurement for the perceived differences between words. Abstract words have a broad mental image due to them being less visually defined, while concrete words with a rather narrow visual feature space are visually easier to grasp. We cooporate this idea into the model and look for feature variety differences of large datasets for different words.
Comparing various modalities like vision, language, and phonemes, we explore differences of perception regarding words when it comes to each modality.
[Sources and pretrained model] https://github.com/mkasu/imageabilityestimation
[Our results and dataset] https://github.com/mkasu/imageabilitycorpus
Finished Doctor in AY2024
Cooperative Research Fellow (Hiroshima City University)